
Forschung und Projekte
Hier finden Sie eine Übersicht über alle aktuellen Forschungsarbeiten und Projekte, sowie eine Auswahl bereits abgeschlossener Projekte und Arbeiten. Bei Interesse melden Sie sich bitte direkt beim aufgeführten Ansprechpartner oder verwenden einen entsprechenden weiterführenden Link.
ScalNEXT
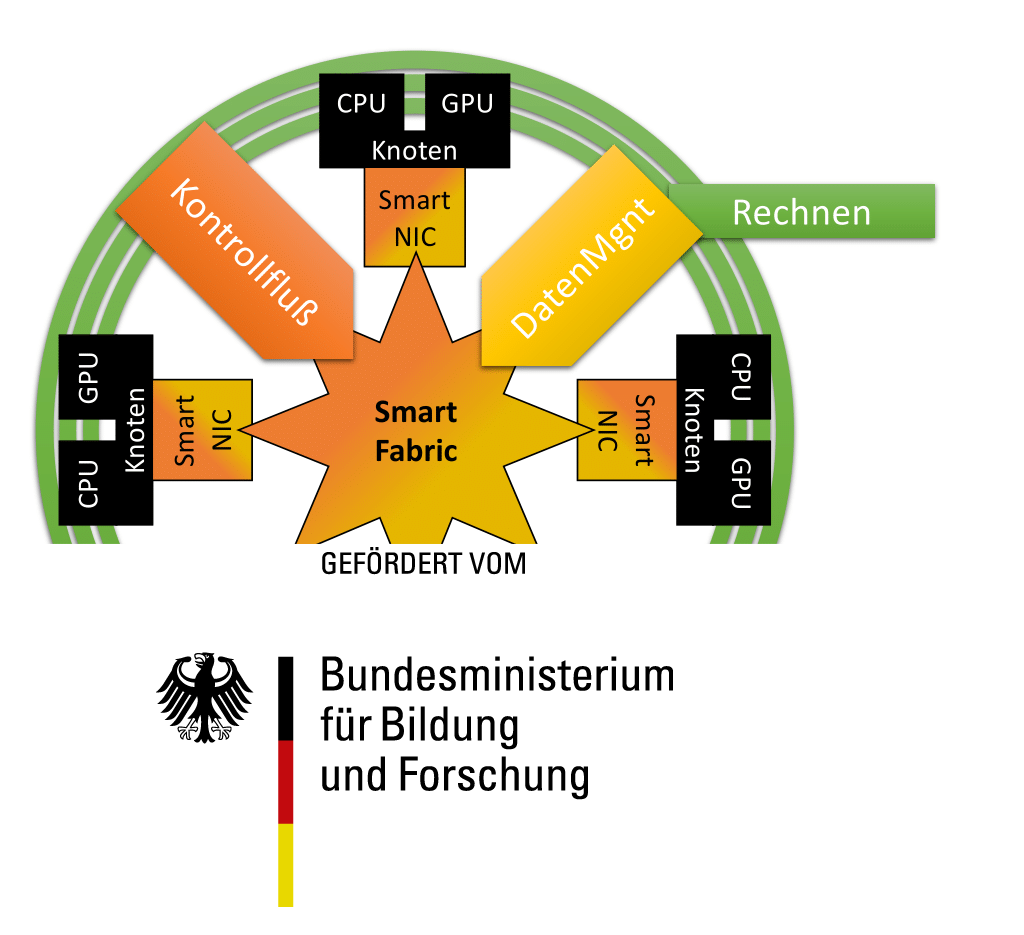
Förderung: BMBF
Projektbeginn: 01.09.2022
Projektende: 31.08.2025
Projektgruppe: Prof. Dr. Wolfgang Karl
Ansprechpartner:
Das Forschungsvorhaben ScalNEXT – Optimierung des Datenmanagements und des Kontrollflusses von Rechenknoten für Supercomputing ist ein vom Bundesministerium für Bildung und Forschung (BMBF) im Rahmen des Förderprogramms „Hoch- und Höchstleistungsrechnen für das digitale Zeitalter 2021-2024 – Forschung und Inventionen zum High-Performance Computing“ auf dem Gebiet „Neue Methoden und Technologien für das Exascale-Höchstleistungsrechnen“ gefördertes Verbundprojekt der JGU Mainz, der RWTH Aachen, der TU München und des KITs mit dem Industriepartner APS Networks.
Anytime Prediction in Neural Networks
Das Projekt beschäftigt sich mit der dynamischen Anpassbarkeit der Inferenz-Geschwindigkeit von Neuronalen Netzen. So soll es in Zukunft möglich sein, zur Laufzeit auf Änderungen von Randbedingungen zu reagieren.
Mehr dazu...
Projektgruppe: Prof. Dr. Wolfgang Karl, Roman Lehmann
Ansprechpartner: Roman Lehmann
Fax-FLOWnet
Das Projekt beschäftigt sich mit alternativen Ansätzen zum Lösen von Differentialgleichungen im Kontext der Strömungsmechanik. So werden mit Verfahren aus dem Bereich des maschinellen Lernens alternative Herangehensweisen erschlossen.
Projektbeginn: 01.01.2020
Projektgruppe: Prof. Dr. Wolfgang Karl, Roman Lehmann
Ansprechpartner: Roman Lehmann
Links: Jobs - Abschlussarbeiten
HALadapt
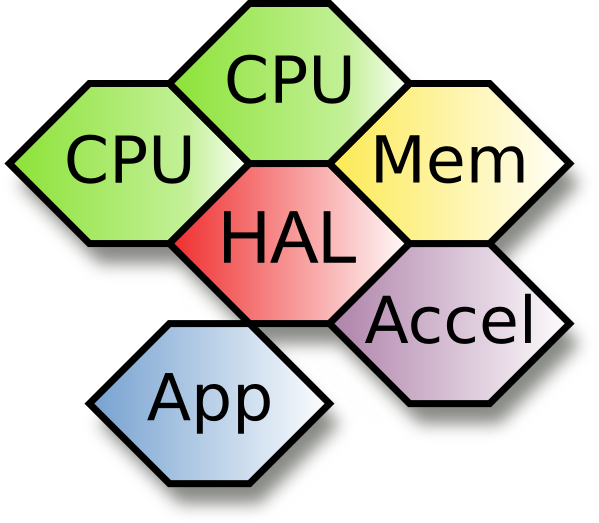
Das Projekt HALadapt beschäftigt sich damit, einem Anwendungsentwickler die Komplexität der Verwaltung eines heterogenen Parallelsystems zu verbergen, sowie durch gezielte Optimierungen Beispielsweise den Energieverbrauch oder die Ausführungszeit von Anwendungen zu senken.
Projektbeginn: 01.01.2016
Projektgruppe: Prof. Dr. Wolfgang Karl
Ansprechpartner:
Links: Jobs - Abschlussarbeiten
Approximative Scientific Computing

Approximate Computing und wissenschaftliches Rechnen sind zwei auf den ersten Blick unvereinbare Themenfelder. Es zeigt sich jedoch, dass diese beiden Gebiete einander nicht nur ergänzen, sondern auch verbessern und weiter entwickeln können. Beispielsweise können ausgesetzte Synchronisationsmechanismen zu effizienteren Lösern linearer Gleichungssysteme führen oder Verfahren wie automatisches Differenzieren Ansatzpunkte für Approximationsstrategien aufzeigen.
Projektbeginn: 01.01.2015
Projektgruppe: Prof. Dr. Wolfgang Karl, Markus Hoffmann
Ansprechpartner: ,
Links: Jobs - Abschlussarbeiten
Projekt KIT - Lehre Hoch Forschung Plus
Im Rahmen des Projektes "KIT Lehre hoch Forschung", gefördert durch das Bundesministerium für Bildung und Forschung (BMBF), widmete sich die Forschungsgruppe für Rechnerarchitektur und Parallelverarbeitung der interdisziplinären Mathematikausbildung sowie der Entwicklung moderner Lehr-Lernplattformen. Aktuelle Problemstellungen aus laufenden Forschungsaktivitäten der Forschungsgruppe aus den verschiedenen Bereichen wie parallele Programmierung mit verschiedenen Programmiermodellen (wie zum Beispiel MPI, OpenMP, Cuda, OpenCL) flossen in das Praktikum mit ein. Beispielhaft wurden forschungsnahe Anwendungen aus unterschiedlichsten Bereichen der Partiellen Differentialgleichungen und im speziellen der Strömungsmechanik in dem Praktikum betrachtet. Zum Lösen dieser Probleme wurden moderne mathematische Ansätze vermittelt und die Verwendung von Hochleistungsrechnern an praktischen Beispielen erklärt. In Kleingruppen wurden projektbasiert Problemstellungen bearbeitet, die Ergebnisse in einem Bericht dargestellt und im Rahmen von Abschlussvorträgen präsentiert. Zudem wurde eine interaktive Lehr- und Lernplatform entwickelt, welche den Lehrstoff des Praktikums visuell aufbereitet und es den Studierenden ermöglicht, die theoretischen Grundlagen im eigenen Lerntempo zu erfassen und an praktischen Aufgaben umzusetzen.
Projekt Envelope
Envelope, kurz für Effizienz und Zuverlässigkeit: Selbstorganisation in HPC-Systemen, war ein vom Bundesministerium für Bildung und Forschung (BMBF) auf dem Gebiet „Grundlagenorientierte Forschung für HPC-Software im Hoch- und Höchstleistungsrechnen“ im Rahmen des Förderprogramms „IKT 2020 – Forschung für Innovationen“ gefördertes Verbundprojekt der JGU Mainz, der RWTH Aachen, der TU München und des KITs. Die übergeordneten Ziele von Envelope waren das Verbergen der Komplexität heterogener Architekturen vor dem Anwendungsprogrammierer, die gleichzeitige Ermöglichung einer effizienten Nutzung der zur Verfügung stehenden Ressourcen in Bezug auf Anwendungslaufzeit und Energie und eine Erhöhung der Zuverlässigkeit und Ausfallsicherheit. Dabei wurde ein Ansatz verfolgt, welcher das System auf mehreren Ebenen betrachtet und Proaktivität ermöglicht. So vereinte der Ansatz die lokale Betrachtung einzelner Knoten mit einer globalen Sichtweise auf das ganze System und Techniken auf der Anwendungsebene. Dabei kamen Methoden aus dem Bereich der Selbstorganisation zum Einsatz, welche sowohl die globale als auch die knoten-lokale Verteilung von Aufgaben an Recheneinheiten übernehmen. Proaktivität wurde mittels der Verwendung von Vorhersagemechanismen zum Ausfallverhalten einzelner Koten erreicht. Diese ermöglichen den zeitnahen Einsatz von Techniken zur Sicherstellung der Betriebsfähigkeit des Systems.
Projekt TahpSE
Das Projekt TahpSE (Task-Scheduling in heterogenen, parallelen Systemen in Echtzeitumgebungen) ist Teil des Förderprogramms Software Campus des Bundesministerium für Bildung und Forschung (BMBF) unter der Initiative Informations- und Kommunikationstechnologie (IKT) 2020. Die Durchführung erfolgt in Kooperation mit einem Industriepartner, welcher im Fall von TahpSE die Siemens AG ist.
Das Ziel von TahpSE war die Erforschung und Analyse von dynamischem Task-Scheduling auf heterogenen und parallelen Architekturen im Kontext von eingebetteten Systemen. Insbesondere erfolgte eine Betrachtung des Sammelns von Laufzeitinformationen und eine Evaluation mehrerer Scheduling-Algorithmen auf einem realen System mit industrienahen Anwendungsszenarien. Weiterhin war die Betrachtung der speziellen Randbedingungen eingebetteter Systeme, wie z.B. die Beschränkung des vorhandenen Speichers, ein wichtiger Aspekt des Projekts. Im Speziellen wurden weiche Echtzeitbedingungen mittels Task-Prioritäten umgesetzt und diese schlussendlich beim Scheduling berücksichtigt. Zusätzlich wurde ein adaptiver Aging-Mechanismus entwickelt und dessen Auswirkungen auf das Task-Scheduling evaluiert.
Projekt Hardware-orientierter Ansatz für BigData
Im heutigen Informationszeitalter werden eine Menge von Daten generiert. Diese sogenannten BigData generierten Daten werden von Sozialen Netzwerken, Telefondiensten, Online-Händlern, aber auch mittelfristig von Sensoren im Bereich Internet of Things generiert. Diese gesammelten Daten beinhalten ein immenses Wissen auf das nicht unmittelbar zugegriffen werden kann. Neben dem großen aufkommenden Datenvolumen sind auch die Variabilität und die Glaubwürdigkeit der Daten ein wichtiger zu berücksichtigender Punkt bei der Analyse solcher Daten. Aktuell wird am Lehrstuhl untersucht, in welchen Bereichen spezielle Hardware-Architekturen die Akquirierung von Daten, die Filterung dieser Daten und die Analyse der Daten beschleunigen oder unterstützen können. Für die Analyse von BigData generierten Daten werden unter anderem Algorithmen der Graph-Theorie und Verfahren des Maschinellen Lernens eingesetzt. Neben textbasierten und graphbasierten Daten werden auch eine Menge an Multimedia-Daten erzeugt. Für die Analyse dieser verschiedenen Datentypen ist die Entwicklung FPGA-basierter Hardware-Architekturen ein sehr interessante Ansatz, um die Komplexität von BigData generierten Daten zu beherrschen. Ein Ziel in diesem Projekt ist der Entwurf einer neuartigen Speicherverwaltung für In-Memory Datenbanken, die Gegenstand aktueller Forschung sind. Diese speziellen Datenbanken werden verwendet, um möglichst schnell auf die Rekords der Datenbank zugreifen zu können. Hierfür können spezielle Hardware-Architekturen entworfen werden, die die Speicherverwaltung des Host-Prozessors unterstützen können.
Projekt Hardware-Beschleunigung für Bioinformatik-Anwendungen
Das Projekt beschäftigt sich mit dem Entwurf von Hardware-Architekturen für Anwendungen aus dem Bereich der Bioinformatik. Für den Entwurf solcher speziellen Hardware-Architekturen bieten sich die am Lehrstuhl verfügbaren Systeme von Convey Computer und Maxeler hervorragend an. Diese heterogenen FPGA-Systeme verbinden die Nutzung von Standard-Prozessoren mit vom Nutzer konfigurierbaren FPGAs. So können diese FPGAs als Coprozessor eingesetzt werden, um spezielle Teile des Algorithmus zu beschleunigen und dem Host-Prozessor zu ermöglichen, parallel an weiteren Teilen des Algorithmus zu arbeiten. Für die Beschleunigung der Suche nach homologen, also artverwandten Proteinsequenzen in einer großen Datenbank wird ein parametrisierbarer Coprozessor für die Convey HC-1 entworfen, der eine beschleunigte Vorfilterung der verwendeten Protein-Datenbank ermöglicht. Des Weiteren wird untersucht, wie die Heterogenität der Convey HC-1 weiter ausgenutzt werden kann, um eine Beschleunigung des verwendeten Algorithmus HHblits zu erreichen.
Projekt TM-Opt
Im Rahmen des - von der DFG geförderten - Projekts "TM-Opt" werden geeignete Methoden und Verfahren zur Analyse und Bewertung sowie zur Optimierung des Laufzeitverhaltens von TM-Anwendungen erforscht werden. Die Analyse und Bewertung betrifft das wechselseitige Verhalten der Transaktionen einer Anwendung zur Laufzeit und das Offenlegen von Konfliktsituationen. Mit den so gewonnenen Informationen soll in der Optimierungphase das Konfliktpotential sich beeinflussender Transaktionen reduziert und damit das Laufzeitverhalten verbessert werden. Dieses Forschungsvorhaben komplementiert die aktuelle Forschung auf dem Gebiet des Transactional Memory.
Projekt Self-aware Memory (SaM)
Self-aware Memory (SaM) ist ein dezentrales und autonom selbst-optimierendes Speicherverwaltungssystem für skalierbare Many-Core-Architekturen mit hoch dynamischen Anwendungszenarien, mit dem Ziel hoher Flexibilität, Zuverlässigkeit und Skalierbarkeit des Gesamtsystems. Forschungaspekte sind eine skalierbare und dynamische Allokation von privatem und gemeinsamem Speicher, effiziente dezentrale Synchronisationsmechanismen, Unterstützung für Transactional Memory und ins Besondere die autonome Selbstoptimierung des Speichers, z.B. einer Lokalitätsoptimierung.
Zusätzlich zur Speicherverwaltung wird eine dezentrales Ressourcenmanagement zur Allokation von Rechenressourcen erforscht.
Projekt Beschleunigung einer Flachwassersimulation für den operationellen Einsatz
Um die Auswirkungen von Dammbrüchen und Überflutungen zu beurteilen, wurde eine verifizierte Flachwassersimulation für das Katastrophenmanagement entwickelt. Da im Falle einer drohenden Gefahr die Ergebnisse einer solchen Simulation möglichst schnell vorliegen sollen, kann nicht auf die Leistung von High-Performance-Clustern zurückgegriffen werden, da diese nicht bei Bedarf zeitnah genutzt werden können.
Um dennoch zeitnahe Ergebnisse auf lokal vorhandenen Systemen zu erhalten, sollen in diesem Projekt Mechanismen entwickelt werden, die die Simulation mittels der folgenden zwei Ansätze automatisch beschleunigen: a) dynamische, ortsabhängige Vereinfachung der numerischen Gleichungen und b) effektive Ausnutzung moderner heterogener Parallelsysteme.
Projekt Self-Organizing and Self-Optimizing Many-Core Architectures
This research project investigates the usage of self-organizing or Organic Computing principles within dynamically reconfigurable many-core architectures. Goal of this project is hiding the complexity of such architectures to the user and easing management and efficient utilization. By using the novel Digital on-Demand Computing Organism (DodOrg) as evaluation platform, research in this project covers all areas of self-organizing systems, ranging from system monitoring up to the realization of a self-optimizing and proactive system behavior.
The DodOrg project is a joint research project and is pursued by 4 cooperating chairs from 3 institutes. It is founded through the DFG Priority Program 1183 "Organic Computing".
Projekt GCC für Transactional Memory
Die vereinfachte Synchronisation mittels Transactional Memory hängt maßgeblich von der Verfügbarkeit eines Compilers mit TM-Unterstützung ab. Für eine flächendeckende Verbreitung und Verwendung von TM ist ein freier, plattformunabhängiger und dem momentanem Stand der Technik entsprechender Compiler zwingend notwendig. Diese Lücke wird durch eine im Rahmen des European Network of Excellence on High Performance and Embedded Architecture and Compilation HiPEAC durchgeführte Kooperation mit der Gruppe von Prof. Albert Cohen am INRIA Saclay, Frankreich geschlossen. Diese Kooperation zielt auf eine gleichermaßen stabile wie robuste Implementierung der Unterstützung für TM in der Compiler-Suite GCC ab.