
Research and Projects
Here you will find an overview of all current research work and projects, as well as a selection of projects and work that has already been completed. If you are interested, please contact the contact person listed directly or use a corresponding link.
ScalNEXT
Funding: BMBF
Project start: 01.09.2022
Project end: 31.08.2025
Project group: Prof. Dr. Wolfgang Karl
Contact:
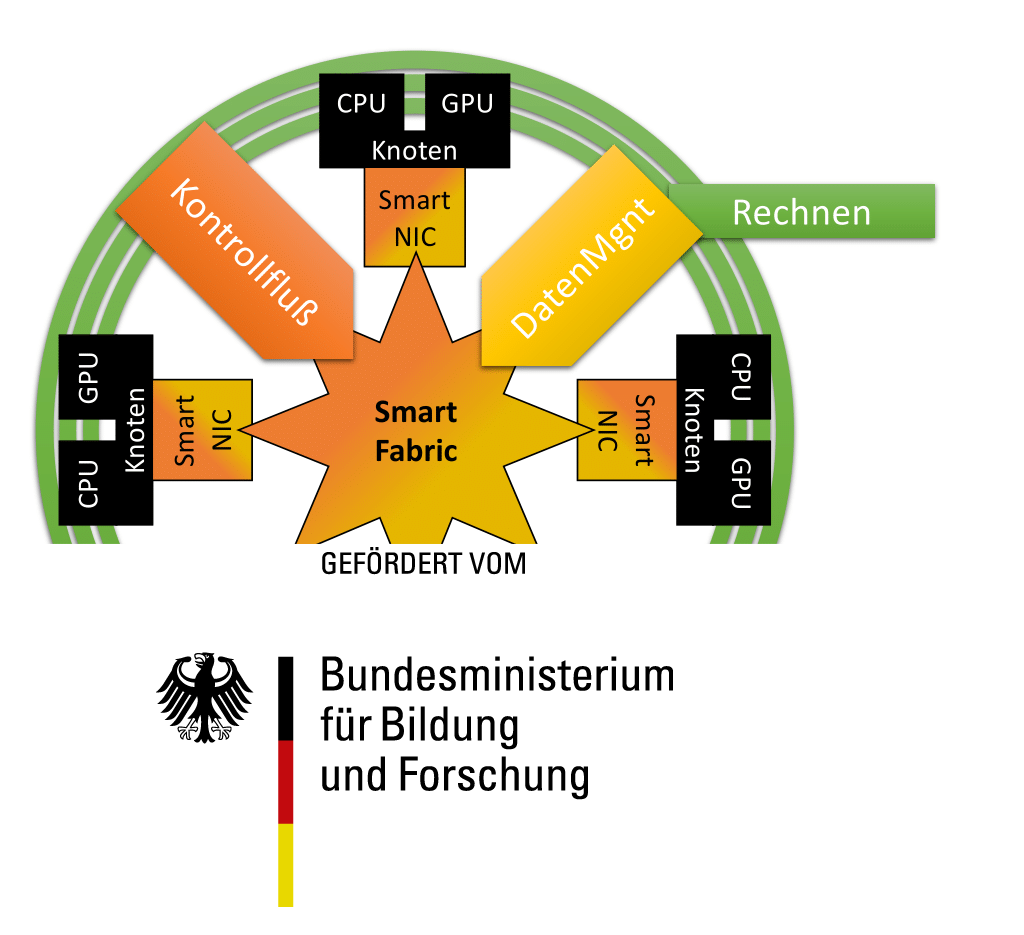
The research project ScalNEXT - Optimization of data management and control flow of computing nodes for supercomputing is a joint project of JGU Mainz, RWTH Aachen University, TU Munich and KIT with the industrial partner APS Networks funded by the Federal Ministry of Education and Research (BMBF) as part of the funding program "High Performance Computing for the Digital Age 2021-2024 - Research and Inventions for High-Performance Computing" in the field of "New Methods and Technologies for Exascale High-Performance Computing".
Anytime Prediction in Neural Networks
The project focuses on the dynamic adaptability of the inference speed of neural networks. In future, it should be possible to react to changes in boundary conditions at runtime.
Project group: Prof. Dr. Wolfgang Karl, Roman Lehmann
Contact: Roman Lehmann
Fax-FLOWnet
The project explores alternative approaches to solving differential equations in the context of fluid mechanics. Here alternative approaches are developed using methods from the field of machine learning
Project start: 01.01.2020
Project group: Prof. Dr. Wolfgang Karl, Roman Lehmann
Contact person: Roman Lehmann
Links: Jobs - Theses
HALadapt
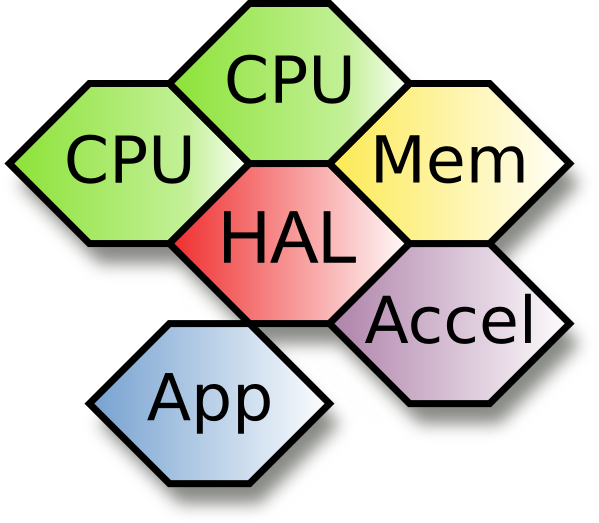
The HALadapt project is about hiding the complexity of managing a heterogeneous parallel system from an application developer and to, through specific optimizations, for example, reduce energy consumption or the execution time of applications.
Project start: 01.01.2016
Project group: Prof. Dr. Wolfgang Karl
Contact person: Dr. Thomas Becker
Links: Jobs - Theses
Approximative Scientific Computing

Approximate computing and scientific computing are two fields that seem incompatible at first glance. However, it turns out that these two fields not only complement each other, but can also improve and further develop each other. For example, suspended synchronization mechanisms can lead to more efficient solvers of linear systems of equations or methods such as automatic differentiation can provide starting points for approximation strategies.
Project start: 01.01.2015
Project group: Prof. Dr. Wolfgang Karl, Markus Hoffmann
Contact persons: Markus Hoffmann, Roman Lehmann
Links: Jobs - Theses
Project KIT - Lehre Hoch Forschung Plus
As part of the "KIT Lehre hoch Forschung" project, funded by the Federal Ministry of Education and Research (BMBF), the research group for computer architecture and parallel processing was dedicated to interdisciplinary mathematics education and the development of modern teaching-learning platforms. Current problems from ongoing research activities of the research group in various areas such as parallel programming with different programming models (such as MPI, OpenMP, Cuda, OpenCL) were included in the practical course. Research-related applications from various areas of partial differential equations and in particular fluid mechanics were studied as examples in the practical course. To solve these problems, modern mathematical approaches were taught and the use of high-performance computers was explained using practical examples. Problems were worked on in small groups on a project basis, the results were presented in a report and presented in final presentations. In addition, an interactive teaching and learning platform was developed, which visually presents the subject matter of the practical course and enables students to grasp the theoretical principles at their own pace and apply them to practical tasks.
Project Envelope
Envelope, short for Efficiency and Reliability: Self-Organization in HPC Systems, was a joint project of JGU Mainz, RWTH Aachen University, TU Munich and KIT funded by the German Federal Ministry of Education and Research (BMBF) in the field of "Fundamental Research for HPC Software in High Performance and Supercomputing" as part of the "ICT 2020 - Research for Innovation" funding program. The overarching goals of Envelope were to hide the complexity of heterogeneous architectures from the application programmer, while at the same time enabling efficient use of the available resources in terms of application runtime, energy, and increasing reliability and resilience. An approach was pursued that considers the system on several levels and enables proactivity. The approach combines a local view of individual nodes with a global view of the entire system and techniques at the application level. Methods from the field of self-organization were used, which take over both the global and the node-local distribution of tasks to computing units. Proactivity was achieved through the use of prediction mechanisms for the failure behavior of individual nodes. These enable the prompt use of techniques to ensure the operational capability of the system.
Project TahpSE
The project TahpSE (Task-Scheduling in heterogeneous, parallel systems in real-time environments) is part of the Software Campus funding program of the Federal Ministry of Education and Research (BMBF) under the Information and Communication Technology (ICT) 2020 initiative. It is being carried out in cooperation with an industrial partner, which in the case of TahpSE is Siemens AG.
The aim of TahpSE was to research and analyze dynamic task scheduling on heterogeneous and parallel architectures in the context of embedded systems. In particular, the collection of runtime information and the evaluation of several scheduling algorithms on a real system with industry-related application scenarios were examined. Furthermore, the consideration of the special boundary conditions of embedded systems, such as the limitation of the available memory, was an important aspect of the project. In particular, soft real-time conditions were implemented using task priorities and these were ultimately taken into account during scheduling. In addition, an adaptive aging mechanism was developed and its effects on task scheduling were evaluated.
Project Hardware-oriented approach for BigData
In today's information age, a lot of data is being generated. This so-called big data is generated by social networks, telephone services, online retailers and, in the medium term, by sensors in the Internet of Things. This collected data contains an immense amount of knowledge that cannot be accessed directly. In addition to the large volume of data being generated, the variability and credibility of the data is also an important point to consider when analyzing such data. The Chair is currently investigating the areas in which special hardware architectures can accelerate or support the acquisition of data, the filtering of this data and the analysis of the data. Algorithms from graph theory and machine learning methods are used to analyze data generated by Big Data. In addition to text-based and graph-based data, a lot of multimedia data is also generated. For the analysis of these different data types, the development of FPGA-based hardware architectures is a very interesting approach to master the complexity of BigData generated data. One goal in this project is the design of a novel memory management for in-memory databases, which are the subject of current research. These special databases are used to access the database records as quickly as possible. For this purpose, special hardware architectures can be designed that can support the memory management of the host processor.
Project hardware acceleration for bioinformatics applications
The project deals with the design of hardware architectures for applications in the field of bioinformatics. The Convey Computer and Maxeler systems available at the chair are ideally suited for the design of such special hardware architectures. These heterogeneous FPGA systems combine the use of standard processors with user-configurable FPGAs. These FPGAs can be used as coprocessors to accelerate specific parts of the algorithm and enable the host processor to work on other parts of the algorithm in parallel. To accelerate the search for homologous, i.e. related protein sequences in a large database, a parameterizable coprocessor for the Convey HC-1 is being designed, which enables accelerated pre-filtering of the protein database used. Furthermore, it is being investigated how the heterogeneity of the Convey HC-1 can be further exploited in order to accelerate the HHblits algorithm used.
Project TM-Opt
As part of the DFG-funded “TM-Opt” project, suitable methods and procedures for analysing, evaluating and optimizing the runtime behaviour of TM applications are being researched. The analysis and evaluation focuses on the mutual behavior of the transactions of an application at runtime and the disclosure of conflict situations. The information obtained in this way is to be used in the optimization phase to reduce the conflict potential of interacting transactions and thus improve the runtime behavior. This research project complements current research in the field of transactional memory.
Project Self-aware Memory (SaM)
Self-aware Memory (SaM) is a decentralized and autonomous self-optimizing memory management system for scalable many-core architectures with highly dynamic application scenarios, with the goal of high flexibility, reliability and scalability of the overall system. Research aspects include a scalable and dynamic allocation of private and shared memory, efficient decentralized synchronization mechanisms, support for transactional memory and, in particular, autonomous self-optimization of the memory, e.g. locality optimization.
In addition to memory management, decentralized resource management for the allocation of computing resources is also being researched.
Project Acceleration of a shallow water simulation for operational use
A verified shallow water simulation for disaster management was developed to assess the effects of dam breaches and flooding. Since the results of such a simulation should be available as quickly as possible in the event of an imminent danger, it is not possible to rely on the performance of high-performance clusters, as these cannot be used swiftly when required.
In order to nevertheless obtain prompt results on locally available systems, mechanisms are to be developed in this project that automatically accelerate the simulation by means of the following two approaches: a) dynamic, location-dependent simplification of the numerical equations and b) effective utilization of modern heterogeneous parallel systems.
Projekt Self-Organizing and Self-Optimizing Many-Core Architectures
This research project investigates the usage of self-organizing or Organic Computing principles within dynamically reconfigurable many-core architectures. Goal of this project is hiding the complexity of such architectures to the user and easing management and efficient utilization. By using the novel Digital on-Demand Computing Organism (DodOrg) as evaluation platform, research in this project covers all areas of self-organizing systems, ranging from system monitoring up to the realization of a self-optimizing and proactive system behavior.
The DodOrg project is a joint research project and is pursued by 4 cooperating chairs from 3 institutes. It is founded through the DFG Priority Program 1183 "Organic Computing".
Project GCC for Transactional Memory
Simplified synchronization using transactional memory depends largely on the availability of a compiler with TM support. A free, platform-independent and state-of-the-art compiler is essential for the widespread distribution and use of TM. This gap is being closed by a cooperation with the group of Prof. Albert Cohen at INRIA Saclay, France, carried out within the framework of the European Network of Excellence on High Performance and Embedded Architecture and Compilation HiPEAC. This cooperation aims at an equally stable and robust implementation of the support for TM in the compiler suite GCC.